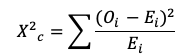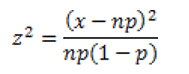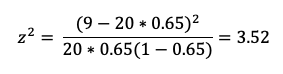4.4.4- Continuas-Distribución Chi-Cuadrado
La distribución X2 (Chi cuadrado) se usa para dos tipos de pruebas:
primero para determinar si los datos de la muestra se ajustan a los de la
población. Segundo, se usa la prueba de independencia Chi cuadrado cuando
se comparan dos variables categóricas en una tabla de contingencia para ver
si están relacionadas o no. La distribución de X2 al igual que
la distribución t-student depende del tamaño de la muestra. Cuanto mas grande
sea el tamaño de la muestra mas se asemejara a la distribución normal. Sin
embargo esta curva se caracteriza por ser asimétrica y sesgada hacia un lado
(izquierda o derecha). Los valores tabulados de la distribución chi-cuadrado
se basan en los grados de libertad (df = n-1), tal como se hace con la distribución
de valores de la tabla t-student. Los valores de Y siguen aproximadamente
la distribución Chi-cuadrado χ2 con k grados de libertad.
Y~χ2(k)
La fórmula usada en la prueba Chi-cuadrado es es:
Donde c son los grados de libertad. O es el valor observado, E
es el valor esperado, i es la iésima posición en la tabla de contingencia
Básicamente lo que hace X2 es mostrar la diferencia existente
entre un valor observado y un valor esperado con un solo número si no hubiera
ninguna relación en la población. Un valor de X2 bajo significa
una alta correlación entre los dos grupos de datos (observados y esperados).
El proceso para determinar si hay una diferencia significativa básicamente
se hace de manera similar que con la distribución de t-student. Si el valor
de X2, es mayor que el valor crítico entonces hay un valor
significativo. Importante tener en cuenta que esta prueba solo puede ser usada con valores reales no en porcentajes ni en proporciones. Es importante anotar que esta es
una fórmula si no dificil si es larga de calcular por la sumatoria de cada
uno de los valores críticos de X2, sin embargo la tecnología
existente nos facilita estos cálculos. En este caso seguiremos
utilizando la hoja electrónica Excel.
4.4.4.1- Bondad del ajuste usando la prueba chi-cuadrado:
Se usa para saber si la muestra se ajusta a los valores esperados. Por
ejemplo, si vamos a comprar un lote de 20 novillas al ojo y el vendedor
nos asegura que los animales han sido todos inseminados. Basados en
información previa se tiene estimada una tasa de preñez del 65% en esa
finca, por lo cual podriamos esperar aproximadamente 13 novillas
preñadas. Sin embargo, al hacer la palpación encontramos que solo 9 de
las 20 novillas resultaron preñadas. El comprador desea estimar si fue
engañado o puede ser normal teniendo en cuenta la tasa de preñez. Para
ello vamos a comparar el valor obtenido con el valor esperado usando la
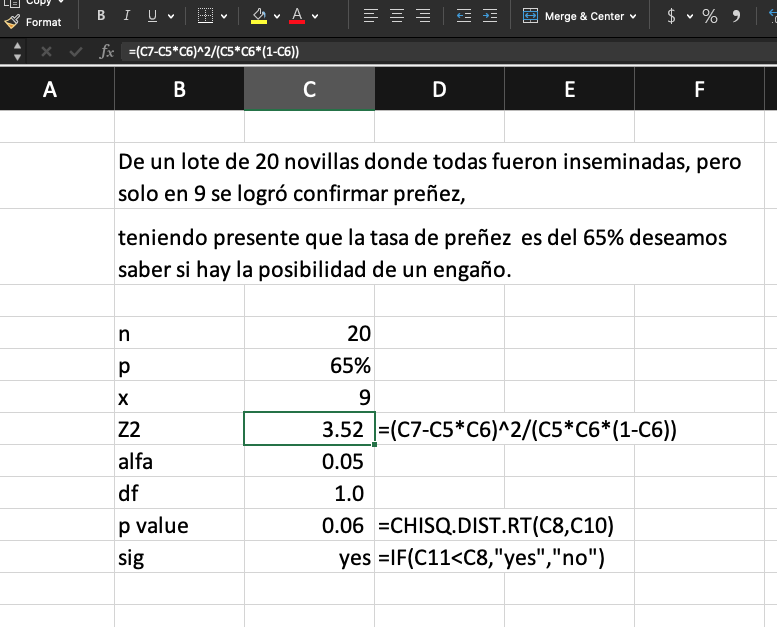
distribucion chi-cuadrado con un 𝝰 del 5%. Para este caso vemos que la
variable X sigue una distribución binomial ya que están o vacías o
preñadas (fracaso - éxito) y el valor calculado z2 se aproxima
a x2. La fórmula para calcular z2 es:
Donde: x es el valor observado, n el numero de repeticiones, p es la probabilidad. Entonces reemplazando:
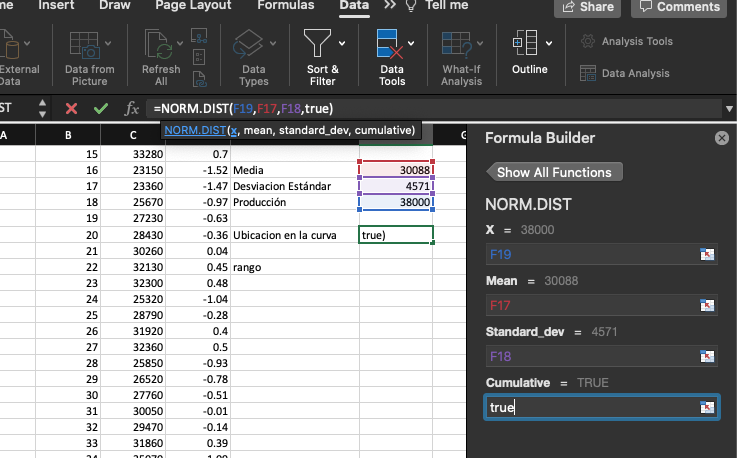
En Excel lo podemos calcular de la siguiente manera:
El valor de z2 lo podemos calcular en Excel siguiendo la fórmula
descrita anteriormente y que se muestra en la celda D8 del recuadro. El valor
de X2 de la tabla lo obtenemos con la función =CHISQ.DIST.RT. Para ello se debe seleccionar el valor calculado de z2 (3.52
en este caso) y los grados de libertad, que en este caso es 1 grado de libertad
(2-1). Como vemos el valor calculado (0.06) es superior al valor de la tabla,
por tanto podemos decir con 95% de confianza que el numero esperado de novillas
preñadas es muy inferior al esperado y el vendedor no cumplió con lo prometido,
por tanto hay que investigar que sucedió.
Explicación de la bondad del ajuste X2
4.4.4.2- Prueba de independencia usando la distribución X2
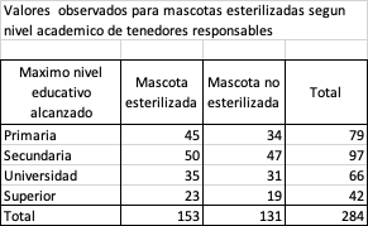
La manera mas sencilla de explicar si dos o mas variables cualitativas son independientes la una de la otra es con un ejemplo aplicado. Para ello vamos a trabajar con un proyecto de tenencia responsable de mascotas. Se está realizando un proyecto de esterilización de mascotas en el sur de Cali (Colombia) y para poder diseñar la campaña de divulgación e información, queremos saber si existe alguna relación entre el nivel de educación de los tenedores responsables y la esterilización de sus mascotas, esto con el fin de saber a que audiencia nos debemos dirigir. Para ello seleccionamos una muestra aleatoria entre los pacientes de varias clínicas veterinarias de la zona. La siguiente tabla de contingencia nos muestra como se dividen los datos de mascotas esterilizadas y no esterilizadas según el nivel educativo de sus tenedores.
Nuestra hipótesis nula (H0): El nivel de educación de los
tenedores no tiene nada que ver con el que la esterilización de las
mascotas.
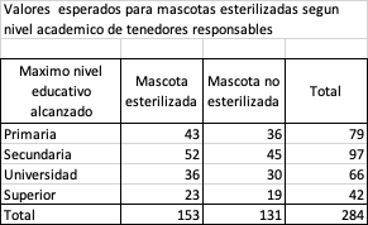
El siguiente paso es calcular los valores esperados para cada una de las casillas presentadas en la tabla de contingencia. Esto lo realizamos para cada categoría multiplicando el total de observaciones de la columna por el total de la fila y dividiendo por el total de observaciones. Por ejemplo el valor esperado para mascotas esterilizadas en el grupo que alcanzó solo hasta educación primaria seria el total de mascotas esterilizadas por el total de personas con educación primaria dividido por el total de observaciones = 153 * 79/284 = 42.55, calculamos entonces los valores esperados para cada casilla. Las sumatorias de las filas y las columnas deben ser iguales a los valores observados en la tabla de contingencia como se observa a continuación:
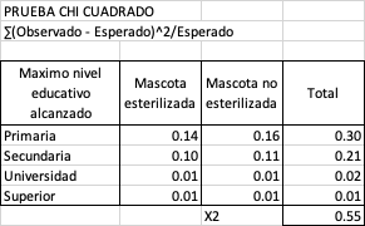
Una vez obtenidos los valores esperados podemos calcular el X2, para ello utilizamos la fórmula:
Haciéndolo paso a paso entonces calculamos el valor de cada grupo y posteriormente sumamos como se observa en la tabla.
El nivel de significancia es de 𝛼 = 5%, los grados de libertad se
calculan: (numero de filas – 1)(numero de columnas - 1) = (2-1)(4-1) =
3. El valor de p lo calculamos utilizando la función de Excel =CHISQ.TEST y seleccionamos para R1 = el conjunto de datos observados y para R2 = el
conjunto de datos esperados. Los rangos de R1 y R2 deben tener el mismo tamaño
y forma y solo pueden contener valores numéricos. Este valor también lo podemos
obtener con la función =CHISQ.DIST.RT, para ello incluimos el
valor de X2 y los grados de libertad.
El valor de significancia p = 0.908 es mayor al alfa 0.05 por tanto no
podemos rechazar la H0 , es decir con un 95% de confianza no existen
diferencias en la cantidad de animales esterlizadas dado el nivel educativo
de los tenedores en esta zona de Cali.
Explicación de la prueba de independencia de la distribución X2