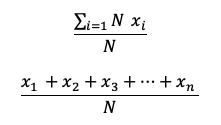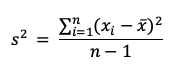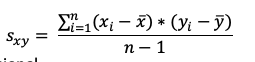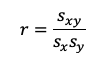5.6 Relaciones entre variables
En la sección 5.3 vimos algunas maneras como podemos visualizar si existe alguna relación entre dos variables. Ahora veamos como se puede medir el grado de relación entre dos variables
5.6.1 Covarianza
La covarianza es una medida de variabilidad conjunta de dos variables. Si la covarianza es positiva esto indica que las dos variables se mueven juntas en la misma dirección. Si la covarianza es negativa entonces las dos variables se mueven en direcciones opuestas. Si la covarianza es 0 las dos variables son independientes la una de la otra. La covarianza puede tomar valores hasta el infinito tanto positivos como negativos. Esto es un problema porque dificulta entender que tan ligadas están las dos variables.
Fórmula de la covarianza muestral
Para la covarianza muestral tenemos que X es la media de la variable X,
x i es la "iésima" posición de esta variable, mientras que Y representa
la media de la variable Y, yi representa la "iésima" posición
de la variable y. Finalmente n representa el número total de observaciones
(suma de observaciones de X y Y).
En Excel para la covarianza muestral se utiliza la función
=COVARIANCE.S si la configuración está en inglés o =COVARIANZA.M en español. Para
la covarianza poblacional las funciones son =COVARIANCE.P o =COVARIANZA.P respectivamente.
5.6.2 Correlación
La correlación es una medida de variación conjunta de dos variables. La correlación busca estudiar el grado de asociación entre variables. También se conoce como correlación lineal de Pearson, es una medida de regresión lineal que pretende cuantificar el grado de variación conjunta entre dos variables. Es importante aclarar que dos variables que están altamente correlacionadas no necesariamente implican que una es causal de la otra (correlación no implica causalidad).
A diferencia de la covarianza, es una medida estandarizada que toma medidas entre -1 y +1 de manera que es mas fácil de interpretar los resultados. Donde valores positivos indican que, si el valor de x sube, el de y sube. Al contrario, si el valor es negativo indica que si x aumenta, y disminuye y un valor 0 es que no hay correlación.
En Excel para la correlación la función =CORREL tanto en español
como en inglés
Fórmula de la correlación
Donde Sxy representa la covarianza entre las variables X y Y (ver
fórmula anterior), Sx es la desviación típica de X y Sy es la desviación típica de Y.
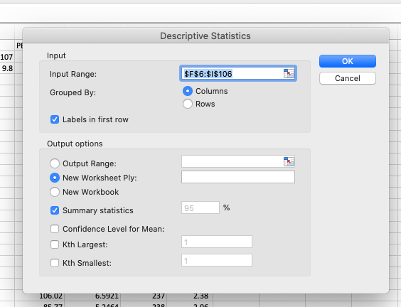
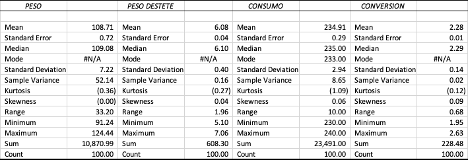
Ejemplo en Excel
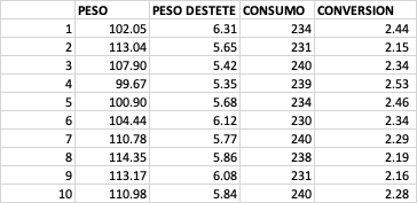
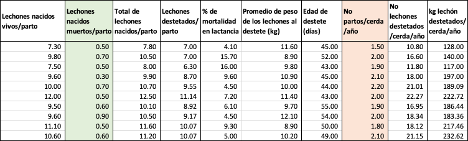
Tenemos los promedios de los registros de producción de 10 granjas de cerdas de cría de una región de Caldas (Colombia) como lo muestra el registro a continuación.
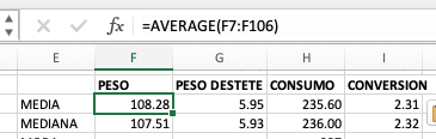
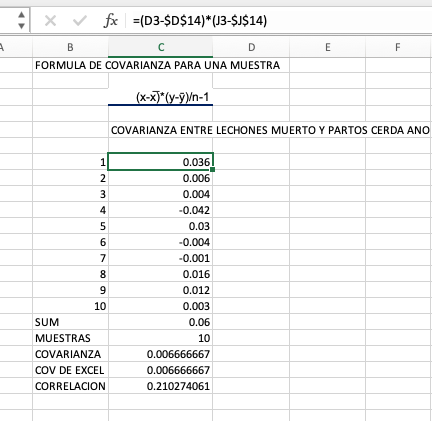
Queremos calcular la covarianza entre lechones nacidos muertos o mortinatos por parto (columna verde) y el número de partos por cerdas por año (columna naranja). Podemos seguir la fórmula de la covarianza muestral y hacer los cálculos en Excel, o bien podemos utilizar la función =COVARIANCE.S (). El resultado va a ser igual como se observa.
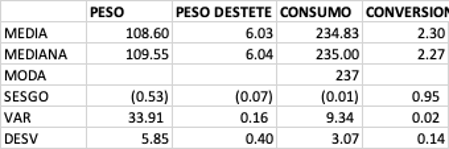
El resultado de la covarianza es positivo 0.0067 lo que nos indica que si hay mas animales por camada tambien hay mas mortinatos por camada. Para cuantificar que tan cercana es la relación entonces acudimos a la correlación, para ello tambien podemos correr la formula o simplemente utilizar la función = CORREL de Excel como se muestra en la tabla superior.
Cálculo de la covarianza muestral